오픈 소스 기반의 비관계형 데이터베이스 관리 시스템인 redis를 사용하려면, 설치하고
어플리케이션에 캐싱을 사용하기 위한 로직을 넣어줘야 합니다.
그러려면 소프트웨어 아키텍처 설계를 해야 하고, 이 과정에서 캐싱을 언제 어떤 과정으로 사용할지 설계가 들어가야 합니다.
그러다보니 캐싱 전략을 사용하지 않는 어플리케이션에서 캐싱을 도입하려면, 어플리케이션에 캐싱할 서비스나 위치에는 많은 수정이 들어가게 됩니다.이를 조금 더 편리하게 제공하기 위해 완전관리형으로 제공하는 aws서비스 중
elasticache와 rdb를 연계시켜 사용할 수도 있습니다.
그러나 조금 더 개념적인 부분에서 캐싱을 어떤식으로 어플리케이션에 구현할 지 다루는
캐싱 전략(Caching Strategies)에 대해 정리해보려 합니다.
레디스를 어떻게 활용하면 좋을까? 같은 활용 방안에 대한 내용도 캐싱 전략을 구체적으로 적용시키는 것이 도움 될 수 있습니다.
캐싱 전략 (Caching Strategies)
캐싱을 활용하는 전략은 개발자들이 개발하며 구분 지은 패턴을 이야기합니다.
특정 방식으로 사용하게 되는 패턴이 있는데 이를 먼저 나열 해보면 다음과 같습니다.
(1) Lazy Loading(jpa? 쓰이는 이름은 같으나 JPA에서 지연로딩과 성격이 비슷합니다. 실제 사용될 때 불러오는)
(2) Read Through
(3) Write Through
(4) Write Around
(5) Write Back
이런 용어들이 있다는 것을 이해하면 될 것 같습니다.
크게 읽기 전략과 쓰기 전략 두 분류로 나눌 수 있을 것입니다.
읽기전략(Lazy Loading, Read Through)
1. Lazy Loading (지연 로딩)
데이터를 읽는 작업이 많을 때 사용하는 전략이며, 레디스를 캐시로 쓸때 가장 많이 사용한다고 합니다.
jpa에서 지연로딩이란, 어플리케이션에서 로딩을 수행하는데 쿼리에 적힌데로 모든 데이터를 읽어와서 수행하는 것이 아니라, 실제 접근이나 읽기가 필요할 때 마다 읽기를 요청하여 값을 받아오는 것 입니다.
특히, 연관관계의 엔티티의 값을 조회할 때 결정하는 전략이며, 한번 가져온 값이 있으면, 영속성 컨테이너 안의 값을 캐싱해서 가져옵니다.
즉시로딩은 엔티티 초기화 시 미리 조건의 값을 읽으며 초기화 한 뒤에, 읽기가 필요한 경우 꺼내서 쓰는 방식입니다.
지연 로딩을 사용하면 엔티티를 조회하는 시점이 아닌 실제 Team을 사용하는 시점에 쿼리가 나가도록 할 수 있다는 장점이 있습니다.
이 덕분에 필요한 만큼만 쿼리를 날려 효율적으로 사용이 가능해 집니다.
한 가지 예를 들자면, 아래처럼 jpql 쿼리를 실행한다고 했을때? fetch join을 수행하지 않았다.
Member findMember = em.createQuery("select m from Member m", Member.class).getSingleResult();
즉시 로딩에서 member와 연관된 Team이 1개여서 Team을 조회하는 쿼리가 나갔지만,
Member를 조회하는 JPQL을 날렸는데 연관된 Team이 1000개라면?
Member를 조회하는 쿼리를 하나 날렸을 뿐인데 Team을 조회하는 SQL 쿼리 1000개가 추가로 나가게 된다.
(this is 1+N)
기본적으로 지연로딩을 사용하면 이런 문제를 해결할 수 있으나, 미리 조회해 두는게 더나은 경우도 있습니다.
fetch join을 사용하나, 지금은 지연로딩 즉시로딩만 정리해 둡니다.캐싱 전략에서 이름이 동일한 jpa에서 지연로딩을 적어봤는데, 그럼 redis에서 사용할 캐싱 전략으로 지연로딩(Lazy Loading)은 어떤 내용일까요??
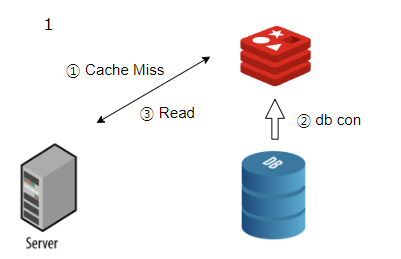
어플리케이션이 데이터를 읽을때, 캐시를 먼저 확인하고,
캐시에 찾는 데이터가 존재하면 캐시에서 데이터를 읽어옵니다.
만약 캐시에 찾는 데이터가 없다면 DB에 접근해서 데이터를 읽어 온 뒤, 캐시에 저장합니다.
요약하자면, 캐시를 먼저 조회, 캐시에 값 없으면 DB 조회 후 캐시에 저장 입니다.
DB를 후순위로 조회한다는 차원에서 지연로딩(Lazy Loading)이라고 합니다.

이 전략을 쓰면, 레디스에 장애 발생 하더라도 어플리케이션에서 다운되지 않고, DB에서 데이터를 가지고 오도록 할 수 있습니다.
대신 캐시에 붙어있던 커넥션이 많이 있었다면, 장애 발생시 그 커넥션이 모두 데이터베이스로 붙기 때문에, DB에 많은 트래픽이 한꺼번에 몰릴 수 있습니다.
그래서 이런 경우에 캐시를 새로 투입하거나, DB에만 새로운 데이터를 저장했다면 캐시에 데이터가 없기 때문에 처음에 Cache miss가 지속적으로 발생해서 DB에 성능에 저하가 올 수 있습니다.
이럴 때에는 미리 DB에서 캐시로 데이터를 밀어 넣어주는 작업을 할 수 있는데. 이를 cache warming이라고 합다.
캐시에 들어가야 할 작업을 요청이 있던 없던 미리 db에서 캐시로 input 시켜주는 작업을 이야기 합니다.
캐시 서비스를 재시작 하거나, 새로 띄우거나 할 때 사용하는 전략입니다.

2. Read Through
데이터 조회 시 캐시를 통해서만 조회합니다.(DB연결은 캐시에서 합니다.)
캐시 미스가 발생한 경우 DB에서 데이터를 가져와 캐시에 넣고, 캐시에서 어플리케이션 으로 값을 받아옵니다.
간단히 말하면, Lazy Loading은 어플리케이션에서 DB를 조회하는 반면 Read Through는 캐시가 DB를 조회합니다.
초기 데이터는 항상 캐시 미스가 발생하므로 cache warming 작업을 해주거나 DB에 데이터 저장 시 캐시에도 쿼리를 수행하도록 설정합니다.
이 결과 데이터 조회는 반드시 캐시로 조회하게 됩니다.
다만 캐시가 다운되면 데이터 조회가 불가능해 어플리케이션 장애로 될 수 있습니다.
그러므로 캐시를 이중화 하거나, 클러스터로 구성하여 가용성을 높여야 합니다.
쓰기전략(Write Through, Write Around, Write Back)
1. Write Through
데이터 생성/수정 시 캐시와 DB에 모두 쓰기 작업을 합니다.
실제로 적용해본 적은 없으나, 어플리케이션을 통해 쓰기 작업이 요청된다면,
캐시에 값을 생성/수정 하면서 DB에도 생성/수정 을 수행하는 것 입니다.
DB부터 적용할 지, 캐시부터 적용할 지 순서는 상황에 맞춰 적용하는게 좋아보이나,
일반적으로 캐시부터 적용 후 DB에 적용 한다고 합니다.
이렇게 하면, 캐시에 최신 데이터가 유지되는 것이 보장되며, DB나 캐시에 문제가 발생했을 때, 손실의 위험을 줄여줍니다.
DB에 데이터가 유실되더라도 캐시에 입력한 내역을 추적하여 값을 복원할 수 있습니다.(로그를 확인하거나 같은)
그러나 캐시와 DB 모두 쓰다보니 쓰기 지연 시간이 증가할 수 있습니다.
쓰기 지연 시간이 증가하더라도 데이터 갱신을 빠르게 하기 위해 캐시에 먼저 데이터를 쓰고 이후 DB에 쓰는 방식을 주로 사용한다고 합니다.(DB먼저쓰더라도 어짜피 캐시에도 적용할 부분이며, 쓰기 지연이 증가하더라도 읽기는 캐시부터 읽는다면, 결과가 빨리 반영되도록 할 수 있기 때문)
사실 얼마나 차이가 날지도 잘 모르지만, 서비스의 규모에 따라 쓰기 지연이 심할 수도 있을 것이므로, 쓰기를 수행하며 캐시와 DB 간의 일관성을 유지하고, 데이터의 신뢰성을 보장하기 위한 방법입니다.

특징
데이터가 항상 최신 상태를 유지할 수 있습니다.
다만 캐싱 된 데이터가 이후 잘 사용되지 않는다면 자원낭비가 될 지도 모릅니다.
그럼에도 데이터가 유실되면 안되는 서비스라면 적합한 전략입니다.
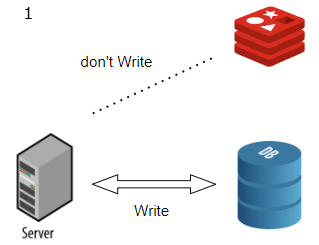
2. Write Around
Write Through와 다르게 입력/수정 발생시, DB에만 갱신하는 전략입니다.
즉, cache에는 입력/수정 하지 않습니다.
간단히 보면 최신 데이터를 출력하기 힘든 전략으로 보입니다.
캐시와 DB의 데이터가 다를 수 있기 때문입니다.
DB에 수정이 일어나더라도, 캐시된 데이터가 수명이 남아 있다면 갱신되지 않고 이전 데이터를 보여줍니다.
최신 데이터를 반드시 보여줄 필요 없고, 특정 기준에 맞춰 데이터가 캐시에 들어가기만 하면 되는 서비스라면
유리한 전략일 것입니다.(예를 들어서 날짜나 시간 단위로 그래프를 출력하는 기능이라면 유리할 것 같습니다.)
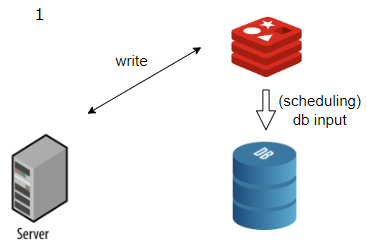
3. Write Back
데이터 Insert 작업이 많이 일어나는 경우, 입력할 데이터를 캐시에 먼저 저장해 놓았다가
DB에 한꺼번에 Insert 쿼리를 실행하는 전략입니다.
다만, 캐시에만 먼저 적용하며 캐시에서 임시로 입력할 데이터를 모읍니다.
스케줄링 작업을 통해 한꺼번에 DB에 저장합니다.(배치)
너무 잘게 데이터가 들어오거나, 쓰기 작업이 빈번한 경우 적합한 전략입니다.
다만 데이터 유실의 가능성을 무시할 수 없습니다.
개인적으로 추천하지 않는 전략이며, 캐시에서 메모리 저장이 아닌 별도 디스크 저장으로 입력 데이터를 모아둔 뒤,
DB에 쓰기하는 방식을 취할 수도 있으나, 여기에선 메모리에만 올려뒀다가 배치처리 하는 것을 말합니다.
그러니 데이터의 유실 가능성이 있습니다.
참고, TTL(Time-To-Live)
각 전략에 TTL을 적용하면 이점을 더 극대화할 수 있습니다.
캐시에 등록 할 때 TTL을 설정하여 key별로 만료시간을 설정 할 수 있습니다.
TTL을 설정하지 않으면, 메모리에 영원히 남아있게 되고 수동으로 삭제해주거나 갱신해야 합니다.
캐시라는 성격상 임시적인 사용을 위해 만료시간을 넣어주는 편이 좋습니다.
위의 전략을 사용하는데 있어 최신 상태를 유지하는데 도움을 주기도 하고, 사용되지 않거나 업데이트 되지 않는 데이터를 자동 삭제하여 자원을 효율적으로 관리할 수 있습니다.
수고하셧습니다. 정리해보면
지금까지 읽기 전략 2개와 쓰기 전략 3개를 정리 해봤습니다.
캐시를 활용하여 읽기에는 어떻게 사용하고, 쓰기에는 어떻게 사용할 지 활용하는 전략을 정의했으며,
읽기 전략과 쓰기 전략을 상황에 맞게 조합하여 개발할 수 있을 거라 생각 됩니다.
처음에 이 내용들이 정말 어렵고 이해가 안되었으나, 이런식으로 정리를 한번 하니 이해가 잘 되는 느낌입니다.
어디가서 설명할 수도 있을 정도로 말이지요.
이후에는 실제로 캐시(redis)를 spring boot 프로젝트에 심어서 예시로 돌려보는 것을 만들어 보려 합니다.
[DB] Redis 특징/활용법/캐싱전략
Key-Value 형태로 저장되는 NoSQL로, 인메모리 데이터베이스이다. 디스크가 아닌 컴퓨터의 주 메모리에 데이터를 저장하기 때문에 보다 빠른 데이터 검색이 가능하다. String, Set, Sorted Set, Hash, List 등
velog.io
[Redis] 캐시란? 캐싱전략? 알고 써보자!
사용자에 입장에서 데이터를 더 빠르게, 더 효율적으로 액세스를 할 수 있는 임시 데이터 저장소를 뜻한다. 대부분의 어플리케이션에서 속도 향상을 위해 캐시를 사용한다고 한다.캐시 저장소
velog.io
'IT기술 > DB' 카테고리의 다른 글
| [Mysql] DBeaver 덤프 옵션 정리 (0) | 2025.02.04 |
|---|---|
| [redis] 캐싱, 활용할 데이터 선정, 고려할 점 (0) | 2024.05.20 |
| [redis] 메모리 기반 캐싱기능을 지원하는 레디스 알아보 (0) | 2024.05.20 |
| [Postgre] AutoCommit 테스트해보기 (0) | 2024.02.23 |
| [DB, JBDC] 데이터베이스 연결, JDBC, SQL Mapper, ORM 정리 (0) | 2024.01.29 |



