DB를 설계한다라...
테이블 만들고 테이블 만들고... 인덱스 잡고...
사실 잘 모르겠다. db에 대해선 전문적으로 공부한 적이 없는 것 같다.
실제로 설계는 해본적이 있으나, 기초적인 지식들 뿐이다보니 방법론이나, 뷰의 활용, 인덱스의 활용
설계시 생각해야 하는 원칙 같은건 알 방법이 없었다.
가르쳐 줄 사람이 없을 뿐만 아니라, 개발할 일이 더 많았기 때문이다.
결국 닥치는데로 해야했으며, 그렇게 경험을 쌓아보니 db설계가 왜 어려운지 실감하게 되었다.
사실 이게 돈이 되는 기술이라 누구한테 배우기도 어렵다.
적어도 내가 생각하기에 공유할 수 있는 부분들을 포스팅 해보려 한다.
- 설계를 하면서 성능적인 면을 고려하는게 좋다.
DB의 역할로써 데이터를 저장하는 기능을 가진다.
이는 비용이 드는 일이다.
비용을 생각한다면 성능을 고려할 수 밖에 없다.
DB의 용량은 어느정도나 가능하고, 얼마나 많은 데이터를 처리할 수 있는가,
cpu, 메모리 같은 하드웨어적으로 여유로운 자원을 통해 활용하면 될 일이지만, 비즈니스 규모에 따라 엄청난 규모의 데이터 처리가 필요할 수도 있다.
여기서 기업에선 비용절감과 원활한 서비스를 원한다.
그렇다면 성능을 신경쓸 수 밖에 없는데, 여기서 설계가 중요한 부분이 된다.
용도에 맞는 컬럼의 크기 제한, 중복된 데이터 저장 안하도록 설정, 데이터 저장 기간 설정, 로깅 할 부분 선택, 백업 용량 설정 등 이부분을 고려해야 한다.
- DB설계 방법
DB를 설계하는데 사용하는 방법이 있다.
크게 상향식 방법과 하향식 방법이 있다.
굳이 이런 방법을 쓰지 않더라도 테이블을 만들고 원하는 컬럼을 추가해서 사용하는 것도 가능하다.
그러나 DB를 설계하는데 있어 설계된 이유가 없는 테이블은 이후에 개비지가 될 가능성이 높다.
이런 이유를 만들어가는 부분에서 위의 방법들을 쓰면 좋은데, 간단하게 정리하면 이렇다.
◆ 상향식 방법
- 요구사항을 분석해 실체를 먼저 도출하는 방식
- 이를 기반으로 필요한 데이터 타입을 분류하여 db를 구성한다.
- 용도에 맞는 DB를 설계하는데 유용하다.
- 새로 만드는 형식으로써 분석 과정과 제작 및 테스트 과정을 거치다보니 오래걸린다.
◇ 하향식 방법
- 이미 만들어진 db를 본떠서 비슷하게 만들어가는 방식
- 사용되고 있는(검증된) 프레임에서 원하는 용도에 맞게 수정해가며 db를 구성한다.
- 필수적인 값들은 원하는 id가 아닌 프레임에 맞춰야한다.
- 테스트및 설계가 상향식 보다 쉬우며 빠르다.
딱 잘라 말하면 상향식은 0부터 시작해 100까지 채워가는 것
하향식은 100에서 깎아낸 뒤 다시 100으로 채워넣는 것
하향식이 빠르고 쉬울 수 있다.(예외도 있겠지만)
어느방법이 맞다 틀리다 라고 할 수는 없다. 두 방법 다 유용한 방식이다.
상향식 방법으로 엔터티를 설계하는 과정
상향식은 조금 더 과정과 손이 많이 들어갈 수 밖에 없는데, 퍼온 예시를 적어보겠다.
※ 엔티티란 : 엔터티(Entity)를 그대로 번역하면 실제, 독립체라는 뜻으로 데이터 모델링에서 사용되는 객체라고 생각하면 된다. 엔터티(Entity)는 업무에 필요하고 유용한 정보를 저장하고 관리하기 위한 "어떤 것(Thing)"이라고 말할 수 있다.
1. 기획안을 보며 모든 키워드를 뽑아낸다.
2. 뽑아낸 키워드를 행위와 데이터로 나눈다.
2.1. 행위와 데이터는 각각 행위 엔터티, 실체 엔터티로 매핑된다.
2.2. 모든 행위나 데이터가 DB에 담겨야하는 것은 아니다. 서버에서 ENUM(상수)로 관리하는 데이터도 있다.
3. 설계한 엔터티에 관계를 매핑한다. 명심할 것은 관계는 속성이라는 점이다. 속성이 필요한 이유는 엔터티 간의 조인(join)을 하기 위해서이다.
맥도날드 키오스크 테이블을 설계해보자
맥도날드 키오스크 프로그램을 만든다고 가정해보자. 단순히 예시가 아니라 외주를 받아 돈을 받고 프로그램을 만든다고 생각해보자. 기획자가 말하는 모든 요구사항을 구현하기 위해서는 DB에 적절히 데이터가 담길 수 있어야 한다. 편의를 위해 주문, 결제 부분은 제외했다.

악명높은 맥도날드 키오스크
먼저 기획서에 적힌 요구사항을 살펴보자.
- 메뉴를 생성/조회/수정/삭제할 수 있어야 한다.
- 메뉴는 하나 이상의 메뉴그룹과 매핑될 수 있다.
- 메뉴마다 가격과 칼로리가 존재한다.
- 메뉴마다 재료를 추가하거나 변경할 수 있다.
- 메뉴는 판매가능한 시간(모닝, 런치)이 존재한다.
- 세트메뉴를 생성/조회/수정/삭제할 수 있어야 한다.
- 세트메뉴는 기본적으로 햄버거 + 감자튀김 + 음료의 조합이다. 대신, 콤보(햄버거 + 음료)처럼 다양한 조합이 나올 수 있다.
- 햄버거를 제외한 나머지 메뉴는 각 그룹 내에서 교환할 수 있다.
1. 기획안을 보며 모든 키워드를 뽑아낸다.
키워드를 모두 뽑아내보면 다음과 같다.
- 메뉴
- 가격
- 칼로리
- 재료
- 재료추가
- 재료변경
- 판매가능시간
- 모닝, 런치
- 메뉴그룹
- 세트메뉴
- 햄버거, 감자튀김, 음료
- 콤보
- 교환
2. 뽑아낸 키워드를 행위와 데이터로 나눈다. 각각은 행위엔터티와 실체엔터티에 매핑된다.
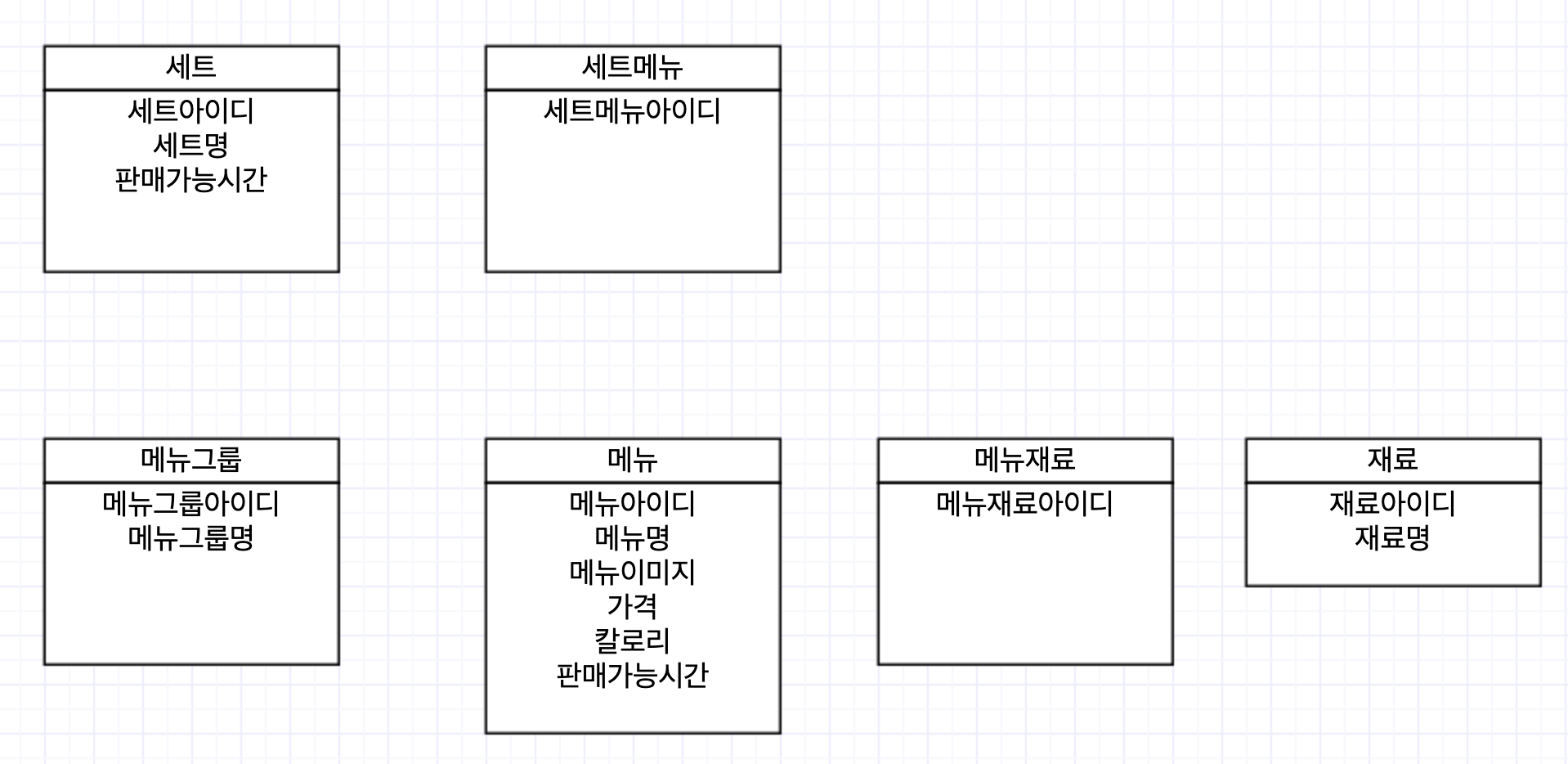
위에 뽑아낸 키워드를 통해 내가 먼저 설계한 실체엔터티는 다음과 같다.
실체 엔터티란
실체 엔터티란 말그대로 실제로 보이는 것을 나타내는 데이터를 관리하는 엔터티를 말한다. 쉽게 말해 만질 수 있는 데이터이면 실체 엔터티이다. 여기선 메뉴, 재료, 세트가 실체 엔터티이다. 메뉴그룹은 실제로 만질 수 없으나 실체 엔터티에 준한다고 생각해 실체 엔터티로 분류했다.
실체 엔터티가 중요한 이유
실체 엔터티는 모델 구조적으로 최상위에 존재하기 때문에 중요하다. 실체 엔터티는 모델의 뼈대를 담당하기 때문에, 실체 엔터티 설계를 잘하면 모델의 근간이 튼튼해진다. 데이터 모델링 과정에서 실체 엔터티를 설계하는 데 가장 많은 시간을 투자해야 한다.

요구사항을 분석하다보면 다대다관계가 존재한다. 위의 요구사항에서는 아래와 같은 다대다 관계를 생각해볼 수 있다.
- 하나의 세트는 여러 메뉴를 가질 수 있다. 메뉴 역시 여러 세트에 속할 수 있다.
- 하나의 메뉴는 여러 재료를 가질 수 있다. 재료 역시 여러 메뉴에 속할 수 있다.
테이블을 설계할 때 다대다 관계라는 개념이 정말 어려웠다. 그러나 실체 엔터티라는 뼈대만 잘 설계한다면 다대다 관계는 어렵지 않다. 그저 테이블을 하나 더 만들면 되는 것이다.
위 요구사항에서 세트메뉴, 메뉴재료라는 다대다 테이블이 생겨났다.
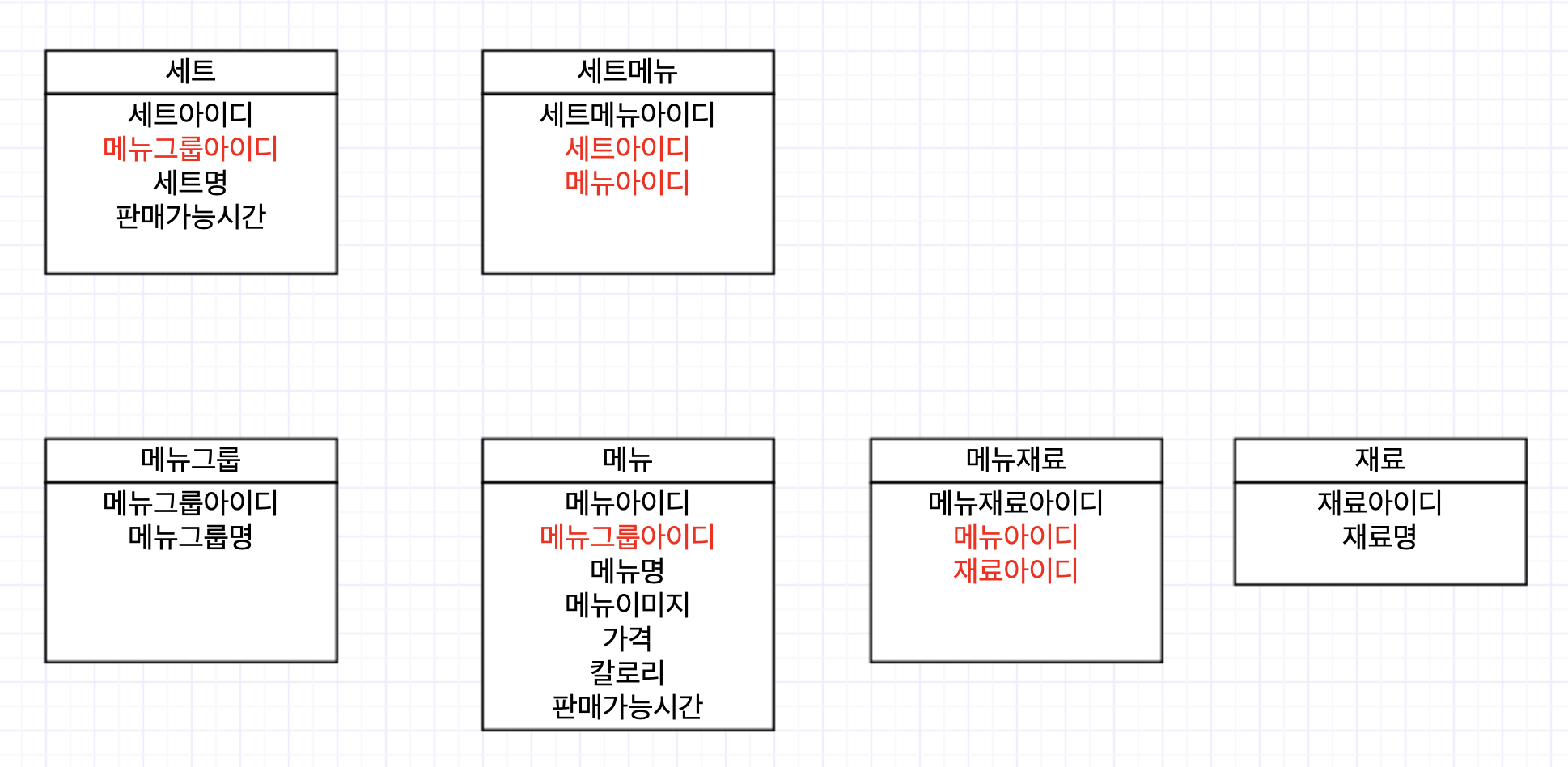
3. 관계를 매핑한다.
이제 엔터티 간의 관계를 매핑할 차례이다. 관계는 그저 엔터티 내 속성일 뿐이다. 그래서 관계선이 없어도 다른 엔터티 내 속성을 갖고 있다면 관계가 형성된다.
아래 빨간색으로 표시한 속성이 바로 그 속성이다.
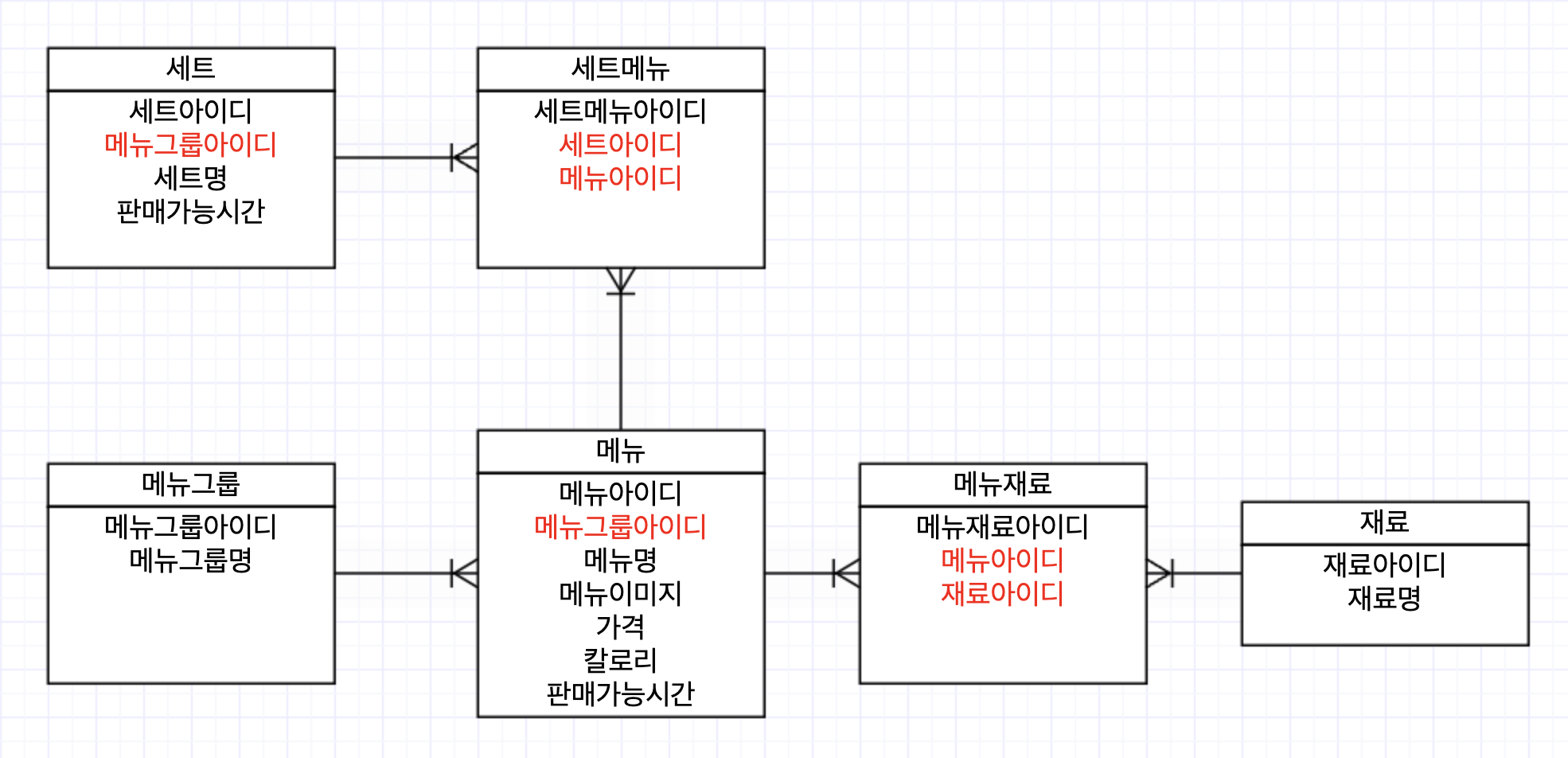
식별관계와 비식별관계
관계를 매핑할 때 알아두어야 할 개념이 있다. 바로 식별관계와 비식별관계이다.
식별관계는 부모 테이블의 기본키를 자식 테이블의 기본키(=PK)로 설정하는 방식이다. 이와 반대로, 비식별관계는 부모 테이블의 기본키를 자식 테이블의 외래키(=FK)로 설정하는 방식이다. 위에서 세트메뉴, 메뉴재료는 식별관계로 설정했고 세트, 메뉴는 비식별관계로 설정했다.
현업에서는 보통 식별관계보다 비식별관계를 선호한다. 그 이유는 구조 변경에 용이하기 때문이다. 즉, 식별관계는 자식 엔터티가 늘어날 수록 주키가 계속해서 쌓이기 때문에 구조를 쉽게 변경할 수 없다.
마지막으로 관계선을 만들면 완성이다.
'IT기술 > DB' 카테고리의 다른 글
| [sql] 윈도우 함수, 알고 넘어가기 (0) | 2023.07.17 |
|---|---|
| [sql] join 문법 정리, inner join, outer join (0) | 2023.07.14 |
| [sql] group by, partition by 사용방법, 그룹화/ 묶어서 표현하기 (0) | 2023.07.14 |
| [sql] NULL 널? 개념, NULL 중요도와 연산, 선택, NULL관련 함수 종류, NULL 정렬 (널 사랑하겠어) (0) | 2023.07.13 |
| mysql datetime 유형 선택하기 (0) | 2021.09.03 |


